 Photo by
Photo by Working with databases means writing queries, getting results, measuring performance, and then optimizing. The cycle never ends. Luckily, for Entity Framework Core 5 (EF Core) users, we have a few options for optimizing our queries. With an IDE like JetBrains Rider, we have tools to understand the benefits we get from our code changes.
Using Dynamic Program Analysis (DPA), we will test what impacts object tracking, streaming, and buffering have on our application’s memory usage.
Streaming Vs. Buffering
When working with an IQueryable instance, we have two options: We can immediately material our results or choose to stream the information into memory. Microsoft documentation explains the differences:
In principle, the memory requirements of a streaming query are fixed - they are the same whether the query returns 1 row or 1000; a buffering query, on the other hand, requires more memory the more rows are returned. For queries that result in large resultsets, this can be an important performance factor. –Microsoft Docs
The crucial words from the documentation are “in principle”. Well, let’s create a sample and see what JetBrains Rider says about memory allocation and usage.
SQLite Code Sample
To start, I generated 1,000,000 Movie entities and stored them in an SQLite database. I’ve written previously about generating EF Core data using Bogus, which I highly recommend reading if you’re interested in creating real-world data.
Let’s look at our EF Core model; this may look familiar from my previous post about value converters.
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Linq;
using Microsoft.EntityFrameworkCore;
using Microsoft.EntityFrameworkCore.Storage.ValueConversion;
using Microsoft.Extensions.Caching.Memory;
namespace EFCoreValueConverters
{
public class Database
: DbContext
{
public DbSet<Movie> Movies { get; set; }
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
optionsBuilder
.UseSqlite("Data Source=movies.db");
base.OnConfiguring(optionsBuilder);
}
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
var converter = new ValueConverter<StreamingService, string>(
from => from.Id,
to => StreamingService.All.FirstOrDefault(s => s.Id == to)
);
modelBuilder
.Entity<Movie>()
.Property(m => m.StreamingService)
.HasConversion(converter);
base.OnModelCreating(modelBuilder);
}
}
public class Movie
{
public int Id { get; set; }
public string Name { get; set; }
public StreamingService StreamingService { get; set; }
}
public record StreamingService(string Id, string Description, string WebSite = null)
{
public static StreamingService Netflix { get; }
= new("netflix", "Netflix streaming service");
public static StreamingService Hulu { get; }
= new("hulu", "Hulu");
public static StreamingService HBOMax { get; }
= new("hbo-max", "HBO Max");
public static StreamingService DisneyPlus { get; }
= new("disney-plus", "Disney+");
public static StreamingService AppleTvPlus { get; }
= new("apple-tv-plus", "Apple TV+");
public static IReadOnlyList<StreamingService> All = new[] {
Netflix,
Hulu,
HBOMax,
DisneyPlus,
AppleTvPlus
};
}
}
Now that we have our data model let’s write the code DPA will watch for memory allocations.
using System.Linq;
using System.Threading.Tasks;
using EFCoreValueConverters;
using Microsoft.EntityFrameworkCore;
using Database = EFCoreValueConverters.Database;
await using var db = new Database();
var movies = db.Movies;
await Streamed(movies);
// not necessary
// but let's make sure
db.ChangeTracker.Clear();
await Buffered(movies);
static async Task Streamed(IQueryable<Movie> movies)
{
foreach (var movie in movies) {
}
}
static async Task Buffered(IQueryable<Movie> movies)
{
var results = await movies.ToListAsync();
foreach (var movie in results) {
}
}
All the code is doing is either materializing our results or iterating over them. Let’s run this code and see what the differences are between streaming and buffering our results.
For our streaming data, we allocate 1,268.7 MB of memory.
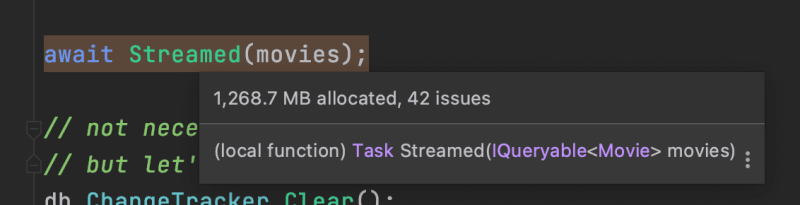
What about buffering? In the buffered scenario, we allocate 1,219.4 MB. We end up allocating 49 MB less!

What happens when we disable object tracking?
await using var db = new Database();
var movies = db.Movies.AsNoTracking();
Rerunning our sample, we can now see that the streaming scenario allocates 559.6 MB of memory.
![]()
And that our buffered sample allocates 579.1 MB, an increase of 20 MB.
![]()
EF Core 5 has introduced a new method of not tracking models but still maintaining identity resolution. What impact does that have on memory? Let’s try modifying our query yet again.
await using var db = new Database();
var movies = db.Movies.AsNoTrackingWithIdentityResolution();
In this case, streaming allocates 1,267.0 MB while buffering allocates 1,294.6MB
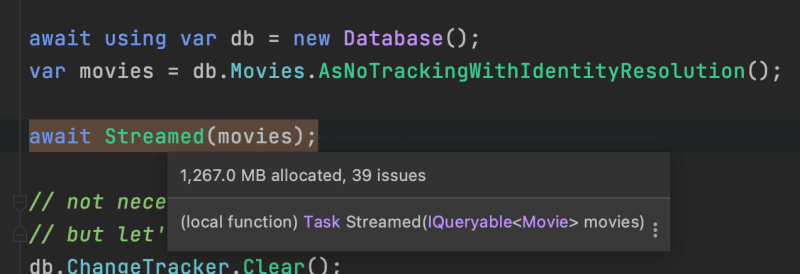
DPA showing us the buffered allocation.
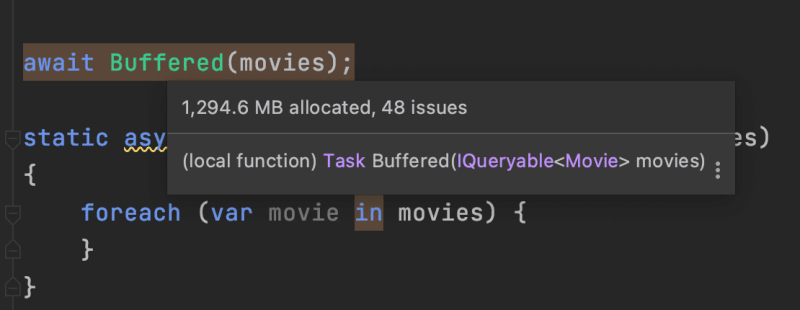
SQL Server Code Sample
I wanted to make sure that the differences, or lack thereof, were not coming directly from the provider. So I switched from using SQLite to EF Core’s SQL Server provider. Here is the code I tested against SQL Server.
using System;
using System.Linq;
using System.Threading.Tasks;
using Bogus;
using Bogus.Hollywood;
using EFCoreValueConverters;
using Microsoft.EntityFrameworkCore;
using Database = EFCoreValueConverters.Database;
await using var db = new Database();
var movies = db.Movies;
await Streamed(movies);
// not necessary
// but let's make sure
db.ChangeTracker.Clear();
await Buffered(movies);
Console.WriteLine("Hi!");
static async Task Streamed(IQueryable<Movie> movies)
{
foreach (var movie in movies)
{
}
}
static async Task Buffered(IQueryable<Movie> movies)
{
var results = await movies.ToListAsync();
int x = 0;
Console.WriteLine($"count: {results.Count}");
}
Some strange results emerged that I was not expecting, especially from the Buffered method. I first ran the test with DPA enabled. The allocations occurring in the Buffered method were not displaying, although Streamed showed similar allocations as previously demonstrated with SQLite. I lowered the threshold to 0 and saw that the method’s memory allocations were 0.7 MB!
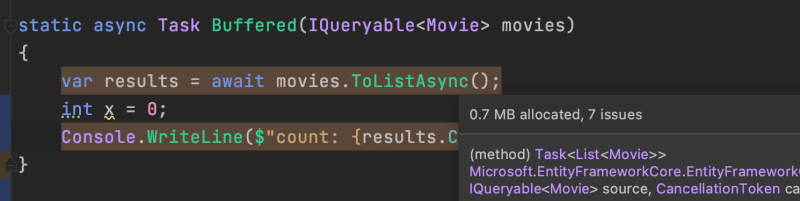
The code change was the most notable memory performance increase I’d seen through my testing. What happens when I change the ToListAsync method back to ToList?

All the allocations come roaring back! It turns out that streaming is a complicated topic, and while extension methods may share similar prefixes, they can behave dramatically differently.
Logging And Allocation
Logging may seem like a harmless addition to the context might also see memory usage explode under extreme circumstances. EF Core has a LogTo method that allows us to redirect logging output to a provider.
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
optionsBuilder
.LogTo(Console.WriteLine)
...
}
Logging will generate unique strings for each record, so folks must be mindful about enabling or disabling this feature. That said, the memory allocations and management are subject to the logging provider implementation. It’s important that we understand that logging may be utilizing more resource than we intended, and it could be the cause of our performance issues.
Conclusion
The most significant memory improvements come from disabling object tracking on queries and utilizing async methods. EF Core object tracking creates many objects to manage the state of our entities. By opting out of object tracking, we ask EF Core to do a lot less. Additionally, Async suffixed methods seem to stream data, while other extensions are hit or missed. It’s also important to understand that streaming is provider-specific, and any performance gains will be unique across databases.
Retry strategies, database engine choice, and other factors can negate the benefits provided by streaming. As always, it is good to measure any optimization and ensure it’s delivering on the promise.
As always, measure to ensure that any assumption about performance and memory allocation are real. Code changes may “work” in principle, but real-world circumstances can force strange behaviors that can set us back.
Have you tried buffering or streaming your EF Core queries? What did you find? Let me know in the comments. I’d love to hear about your experience. As always, thanks for reading.


