 Photo by
Photo by I maintain an open-source project called ConsoleTables. It’s a silly little project meant to help you take a collection of data and quickly dump it into your terminal session. I started the project so long ago that the reason I created it is lost to the sands of time. That said, it’s seen wild adoption by many, and there’s a continuing issue that folks come back with repeatedly: handling non-ASCII characters. Non-ASCII characters can do strange things to your output.
In this short post, we’ll see how you can calculate the actual length of a string using the StringInfo class and why writing to the console might be one of the most complex technical challenges of our time. Well, maybe not, but it’s still damn hard.
Non-ASCII Characters
What do I mean when I say “Non-ASCII” characters? ASCII is a table of numeric values from 0 to 127 that represent characters found in the English language, along with values for familiar computer characters such as Space, Delete, and Escape. Let’s see what that table looks like.
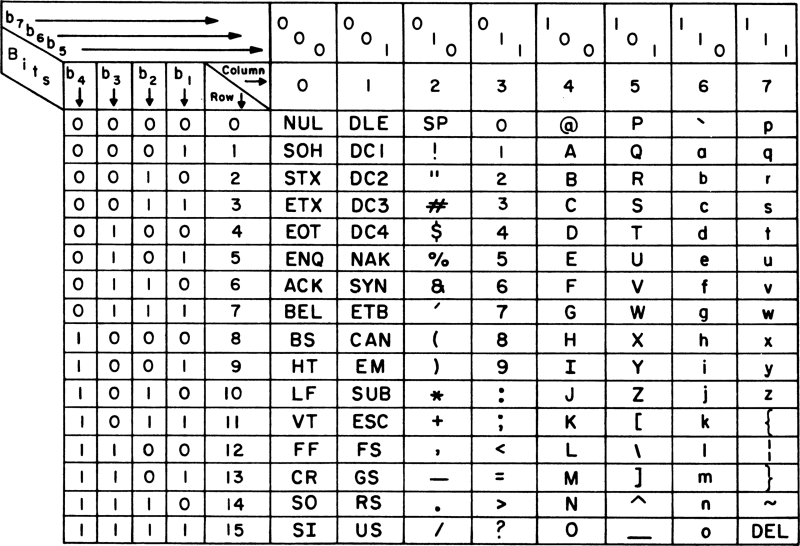
Simple. Well, it is for English speakers, but other languages and symbols exist and are essential to represent all the collective knowledge of mankind. This is why Unicode exists, providing a set of characters for modern and historic scripts, symbols, and thousands of emojis. You know, emojis, the kind you send your partner 😘. There are nearly 150,000 characters in Unicode, a far cry from the humble 127 of ASCII, and far too many to display in a chart for you here.
With the variety of characters comes a visual problem for folks rendering them into a terminal output. How many “spaces” does a character take up? In most cases, we hope all characters take up one space, but that’s only sometimes the case. How do we determine the length required to display a Unicode character with C#?
Let’s see some code that attempts to solve just that problem.
System.Globalization.StringInfo and Lengths
Let’s look at a collection of string instances in an array. Visually, to your human eye, how many spaces would you say each is?
var characters = new[] { "a", "1", "👩🚀", "あ", "👨👩👧👦", "✨" };
You might say, “Khalid, they’re all definitely one character long! Do you take me for a fool?!” Well, no, I respect you; please don’t hurt me. My question frames the point that appearances can be deceiving, and only a few values are 1 in length. Let’s take at the console output for each string value and look at our output.

What the heck is going on? Ugh. Well, by using System.Globalization.StringInfo, we can determine if we’re dealing with a character with more length than is visible to the naked eye by using
using System.Globalization;
var characters = new[] { "a", "1", "👩🚀", "あ", "👨👩👧👦", "✨" };
var lengths = characters.Select(s =>
(value: s, length: StringInfo.GetNextTextElementLength(s))
);
foreach (var (value, length) in lengths)
{
Console.WriteLine($"{value} (length: {length})");
}
Running our code, we can now see the length of each string value, and it’s surprising.

Why is this happening?! Well, some Unicode characters build on other existing characters. For instance, the Woman Cosmonaut combines the 👩 + U+200D + 🚀. The two emojis and the zero-width divider are 5 characters in length. The family emoji has 11 characters because of this combination:
That’s a lot of characters!
So what can you do to work around this issue? Well, not much. The terminal determines how it displays the values. This can lead to frustration when building a Console-focused library, as you will be chasing issues depending on your user’s development environment.
Luckily, we can use System.Globalization.StringInfo to see those invisible spaces that Unicode values may bring, but sadly, there isn’t much we can do from the C# side to fix the display output, as it would mutate the values we’re dealing with.
I hope you enjoyed this post, and thank you for reading and sharing all my blog posts with friends and colleagues.


