 Photo by
Photo by If you make your living as a software developer, you undoubtedly have had to deal with databases. In my case, I primarily work with Microsoft SQL Server and specifically the Windows Azure permutation. For simple applications, you may find Object Relation Mappers like Entity Framework, a fine enough solution.
Unfortunately, the world is a complicated place, and users are an excellent problem to have. What if I told you that your application could increase performance, reduce cloud expenses, and make your DBAs happy?
In this post, I will show you how to use multiple result sets to do the following:
- Reduce the complexity of queries
- Reduce the utilization of database resources
- Reduce Network transfer costs
Let’s get started!
You can also download the project from my GitHub repository.
The Problem
In this post, we’ll be dealing with a simple database that consists of two tables: People and Food. There is a one-to-many relationship between people and food. The tables themselves are unremarkable, and for this post, I’m not even worried about the correctness of schema.
create table People (
Id INT,
FirstName VARCHAR(50),
LastName VARCHAR(50),
Email VARCHAR(50)
);
create table Foods (
Id INT,
PeopleId INT,
Name VARCHAR(50)
);
In our dataset, we have an individual named Waylin, and he has eight foods associated with him. Let’s take a look at his data.
select * from People p
inner join Foods f on p.Id = f.PeopleId
where p.Id = 1;
As you can see with our inner join, the individual has eight foods associated with him. Oddly though, we notice that his data repeats eight times on the left-hand side. The result is symptomatic of SQL joins.
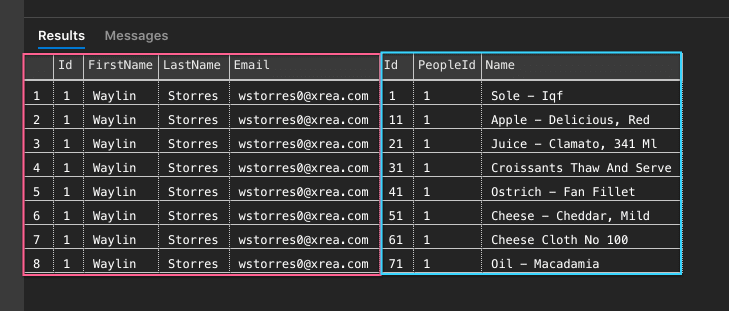
To reduce the size of our result set, we could execute two SQL queries.
select * from People where Id = 1;
select * from Foods where PeopleId = 1;

You notice we have nine rows in total, but not data duplication. The database returns each result separately.
This particular sample is a bit contrived, but in a complex database schema, running more straightforward SQL statements can reduce query time, CPU utilization, and reduce the result set substantially. Running complex joining queries can be a severe bottleneck for application performance. ORMs can be guilty of producing such SQL.
So how can you take advantage of this approach in .NET Core? The following sections show you how to use vanilla .NET alongside popular data access libraries like Dapper, NPoco, and Entity Framework. Although, as you’ll see, Entity Framework is the least pleasant to use.
But first, how do you prime your application to use multiple result sets?
Getting Started
Before attempting to use multiple result sets in your project, first, make sure that your SQL Server version can support it.
SQL Server 2005 (9.x) introduced support for multiple active result sets (MARS) in applications accessing the Database Engine. In earlier versions of SQL Server, database applications could not maintain multiple active statements on a connection. –Microsoft
Firstly, I hope no one is using SQL Server 2005 still, but I can understand if you still are.
Secondly, make sure your data access method is using SqlClient. The class is the default data access method for most .NET libraries accessing a SQL Server instance.
It is important to note that Microsoft is currently moving SqlClient into a NuGet package, so your namespace may be different based on your application.
You can see more about the move on Channel 9.
Finally, and this may be optional, your connection string might need a MultipleActiveResultSets value.
"Data Source=localhost;Initial Catalog=master;Integrated Security=True;MultipleActiveResultSets=True"
I’ve found the addition to the connection string necessary when using the Full Framework, but unnecessary with my setup of .NET Core and SQL Server for Linux.
We use all of the following classes in our examples:
public class Person
{
public int Id { get; set; }
public string FirstName { get; set; }
public string LastName {get;set;}
public string Email { get; set; }
}
public class Food
{
public int Id { get; set; }
public int PeopleId { get; set; }
public string Name { get; set; }
}
Additionally, each approach executes the same SQL statements.
select * from people where id = @id;
select * from foods where peopleId = @id;
Let’s start calling some code!
Multiple Result Sets Using SqlCommand
Out of the box, you can take advantage of multiple results utilizing SqlCommand. The SqlCommand class is the underlying ADO.NET workhorse that many of your favorite data access use. If you want to keep dependencies to a minimum, I recommend this approach.
var command = new SqlCommand(sql, connection);
command.Parameters.AddWithValue("@id", 1);
var reader = await command.ExecuteReaderAsync();
var people = new List<Person>();
var food = new List<Food>();
while (await reader.ReadAsync())
{
people.Add(new Person
{
Id = reader.GetInt32("Id"),
Email = reader.GetString("Email"),
FirstName = reader.GetString("FirstName"),
LastName = reader.GetString("LastName"),
});
}
await reader.NextResultAsync();
while (await reader.ReadAsync())
{
food.Add(new Food
{
Id = reader.GetInt32("Id"),
Name = reader.GetString("Name"),
PeopleId = reader.GetInt32("PeopleId")
});
}
await reader.CloseAsync();
The critical part of the SqlCommand implementation is the call to NextResultAsync. The method lets us move to the next result set. In the example, we have two result sets, so we only need to invoke it once.

Multiple Result Sets Using SqlDataAdapter
If you want a method that is less dependant on C# types, you can utilize the SqlDataAdapter class to fill a DataSet. I like to think of a DataSet as an in-memory database with tables, columns, and rows.
var dataset = new DataSet();
var adapter = new SqlDataAdapter();
var command = new SqlCommand(sql, connection);
command.Parameters.AddWithValue("@id", 1);
adapter.SelectCommand = command;
adapter.Fill(dataset);
var people = dataset.Tables[0].ToList<Person>();
var food = dataset.Tables[1].ToList<Food>();
This approach can be useful for prototyping data access code without the need to create concrete classes. We can access a dataset’s values can via columns and rows. In the example above, I used an extension method to map to our classes.
public static class DataTableExtensions
{
public static List<T> ToList<T>(this DataTable dt)
{
const BindingFlags flags = BindingFlags.Public | BindingFlags.Instance;
var columnNames = dt.Columns.Cast<DataColumn>()
.Select(c => c.ColumnName)
.ToList();
var objectProperties = typeof(T).GetProperties(flags);
var targetList = dt.AsEnumerable().Select(dataRow =>
{
var instanceOfT = Activator.CreateInstance<T>();
foreach (var properties in objectProperties.Where(properties => columnNames.Contains(properties.Name) && dataRow[properties.Name] != DBNull.Value))
{
properties.SetValue(instanceOfT, dataRow[properties.Name], null);
}
return instanceOfT;
}).ToList();
return targetList;
}
}
Here is the result running.

Multiple Result Sets Using Dapper
Dapper is a Micro-ORM developed by StackExchange and is as pure an abstraction over raw ADO.NET as you can get. If you are starting to think about a production implementation, this is a great place to start.
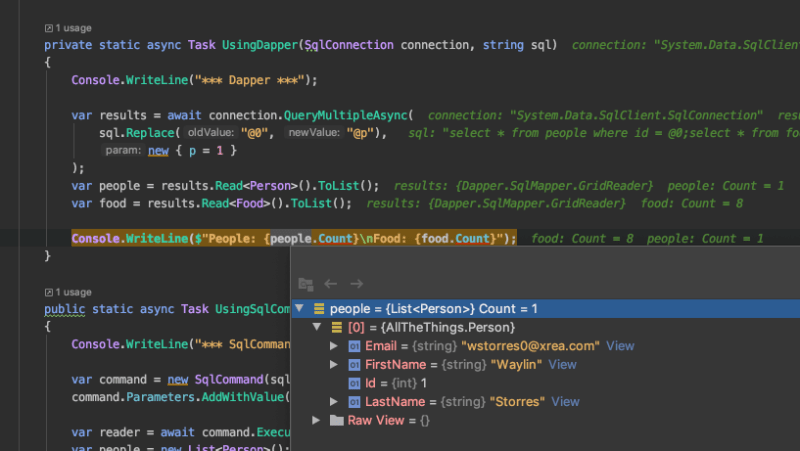
var results = await connection.QueryMultipleAsync(sql,new { id = 1 });
var people = results.Read<Person>().ToList();
var food = results.Read<Food>().ToList();
As you can see, the code is substantially smaller than any other implementation so far. Dapper handles the multiple results query and also maps our results directly to our objects.
Multiple Result Sets Using NPoco
I’m personally a big fan of [NPoco][]. It has a few more implemented details than Dapper does for my day-to-day use. That said, when it comes to multiple results, its implementation is very similar to Dapper.
var database = new Database(connection);
var (people, food) =
database.FetchMultiple<Person, Food>(sql,new {id = 1});
The useful thing about NPoco is that it supports Tuple deconstruction. The results of FetchMultiple are a Tuple<Person, Food>, and we can deconstruct it into two variables for use.
Multiple Result Sets Using Entity Framework Core
Entity Framework Core is Microsoft’s ORM, and for most cases, it works just fine. While it can internally handle multiple results, many of their raw SQL implementations do not expose the interfaces required to iterate over them. The lack of exposure is likely due to the need to support many different types of databases, and the developers didn’t want to create an inconsistent experience across SQL implementations.
I previously wrote about supporting multiple results in Entity Framework 6, but many of those APIs are no longer available in Core. Sadly, the approach I came up with EF Core leaves much to be desired, and I don’t recommend you use this approach.
var database = new MyDbContext();
var connection = database.Database.GetDbConnection();
await connection.OpenAsync();
var command = connection.CreateCommand();
command.CommandText = sql;
command.CommandType = CommandType.Text;
// namespace weirdness
command.Parameters.Add(new Microsoft.Data.SqlClient.SqlParameter("@id", 1));
var reader = await command.ExecuteReaderAsync();
var people = new List<Person>();
var food = new List<Food>();
while (await reader.ReadAsync())
{
people.Add(new Person
{
Id = reader.GetInt32("Id"),
Email = reader.GetString("Email"),
FirstName = reader.GetString("FirstName"),
LastName = reader.GetString("LastName"),
});
}
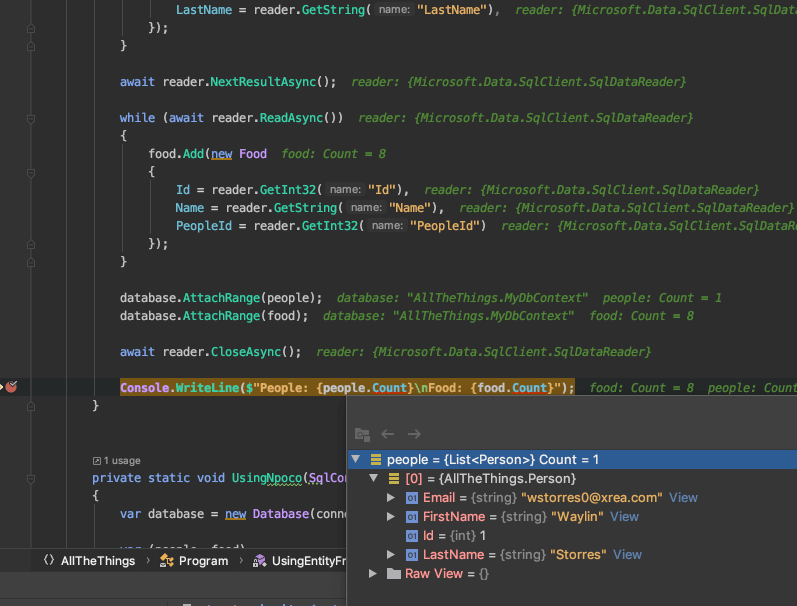
await reader.NextResultAsync();
while (await reader.ReadAsync())
{
food.Add(new Food
{
Id = reader.GetInt32("Id"),
Name = reader.GetString("Name"),
PeopleId = reader.GetInt32("PeopleId")
});
}
database.AttachRange(people);
database.AttachRange(food);
await reader.CloseAsync();
As you may notice, this implementation is very similar to the SqlCommand approach. There are a few main differences.
- We use the connection from our
DbContext. - We create a
DbCommandfrom thatDbConnection. - We attach our models to the
DbContextif we want object tracking to occur.
It’s not ideal, but can be remixed with the other implementations. If I still wanted to use EF Core, I may mix in some Dapper calls when I wanted to optimize some of my more complex queries.
This approach is not as robust as my previous Entity Framework 6 solution. I could not find the internal implementation in EF Core that maps results to classes, and I doubt it would be exposed either.
To create a more robust solution, you may consider using a mapping library like AutoMapper or just rolling your own via reflection.
Conclusion
While the examples may be simple in this post, the ability to utilize multiple results can dramatically change the performance profile of your applications. Let’s go over the advantages again:
- Less resource utilization at the database
- Less complicated SQL statements to the database
- Fewer bytes transferred back over the network to your app
Taking this approach can make you happy, your database administrators happy, and your users ultimately happiest. I hope you’ve found this post insightful and let me know if I missed an approach to take advantage of multiple result sets.
You can also download the project from my GitHub repository.


